Link analysis of IMDB movie connections
Louis, I think this is the beginning of a beautiful friendship
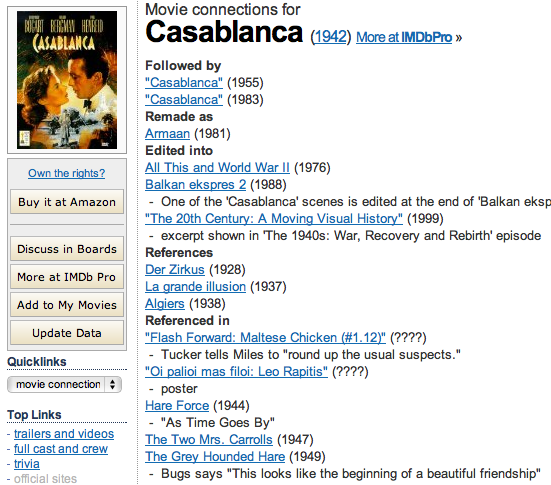
The movie database IMDB is a great source of information, but there is one aspect of it most people don’t know about: most films have a “Movie connections” section, which lists all references to other films (or TV series). What can be considered a reference is pretty open: it could be music, a film poster visible in a scene, or one of the characters uttering a well-known line from another film, like Humphrey Bogart’s words “I think this is the beginning of a beautiful friendship” from Casablanca’s famous ending.
The current IMDB dataset contains around one million of those references, far too many to visualise or comprehend easily. So how could this data be filtered, to get to the interesting films and references?
Rank it
Now, if you look at film references as edges between nodes (films) in a graph you can apply existing algorithms like PageRank to obtain a score for each film, similar to one of the ways Google determines importance of web pages. An intentional reference to another film is similar to citation in a book, or a link to another web page.
I have had the idea to use graph algorithms to analyse the IMDB movie connections for a while now but only started building something until quite recently. Then, after a few days of coding and just before publishing this blog article I saw that somebody else had done more or less the same work, a few months earlier: in the blog post “The most important movies of all time”, Thore Husfeldt presents a list of important movies as determined by his FilmRank algorithm which is (as the name suggest) pretty similar to PageRank.
The tl;dnr version of the blog post: PageRank on a movie reference graph produces lists very similar to top film lists compiled by critics. The list he presents is also similar to mine, so I will not repeat it here.
As always, it is very hard to come up with novel ideas (or even just applications thereof) – there is a very high probability that somebody has already implemented and published “your” idea somewhere on the internet. However there are two things his article is lacking: a graphical representation of the results and the source code to obtain them from the raw IMDB data set.
Pretty graphs and weird numbers
Interestingly, a look at the Top 250 (Google doc / CSV) list reveals a lot of well-known films but also some more obscure ones. How did they get on this list? It’s not really obvious from the list data itself, you need to look at the connections to find out why.

One of the properties of PageRank is that important nodes distribute their importance to all nodes they link to. Now, if a very significant node (let’s say Star Wars) links to a few other nodes, these nodes will be considered important as well. So in order to understand these rankings better we need to look at the links between nodes.
I created a few graphs with the top N films and all the connections in between them, filtering out unconnected nodes. In the graph on the side, I was curious about the film on the left, 21-87. I had never heard of it, but it is obviously ranked highly because Star Wars and THX 1138 refer to it. Both these films were directed by George Lucas (THX 1138 was his first film), so there had to be be some sort of connection.

A quick look at the movie connections page revealed two numerical references (Leia’s Death Star cell number and a date), and a search for “21-87 George Lucas” finds the article “21-87: How Arthur Lipsett influenced George Lucas’s career” which goes on to explain how Lipsett’s experimental short films influenced the sound design of George Lucas’ later films.
I used graphviz to show connections between top ranked films. Graphviz can output SVG, so it was pretty easy to create high quality vector documents which render in most modern browsers (all except Internet Explorer < 9, Android WebKit).
There are a few different versions since more nodes means more edges and therefore less readability (I did not apply any sort of edge pruning):
{kind=link}
{kind=link}
And the raw data:
Films from the same decade are grouped vertically, starting from the 1900s on the left. Tooltips show more information about each film, and each node links directly to the IMDB connections page. Films with bold titles indicate a IMDB Top 250 title. Darker coloured nodes are TV series. Since the SVG standard does not yet have zoom controls you will need to use your browser’s zoom controls.
As a side note, the algorithm used to produce these rankings does not make a distinction between movies or TV series – all links are considered to be of equal importance. This has the interesting side effect that TV series make it into the ranking – almost all top charts (IMDB Top 250 included) do not contain TV productions, although some of them had a big influence on cinema. You might wonder then why the Simpsons (a true reference generating machine) are not part of the graph – although they rank 61st the IMDB data only contains incoming links for them, presumably because they already have their own reference database, the episode guidebook.
Also there is no link dampening applied (downweighting references from a recent film to an old film).
Show me the code
I have released the source code to produce this rankings, which makes it reasonably easy it to create your own experiments and graphs. It is basically just a glue Rakefile with some Python code to do the analysis part (using the excellent NetworkX library). Other requirements are Python (>= 2.6) with IMDbPy, Ruby (>= 1.9) and graphviz.
$ git clone git://github.com/jberkel/imdb-movie-links.git
$ cd imdb-movie-links
$ easy_install networkx imdbpy
$ brew install graphviz wget # OSX/homebrew
$ bundle install
$ rake rank # CSV export ranking
$ rake graph.svg MAX=50 # create a graph, max. 50 nodes
Happy ranking!
What next?
It would be interesting to do this kind of analysis with different media – for example music (look at sample references in a track) or even literature.
The problem is to get a good dataset – the movie example works so well because the IMDB data has been collected by a lot of people, over the course of almost 20 years now.